A Framework for API Data Syncing: The Ontraport to Supabase Case Study
-
Upwork Only
- . November 1, 2025
This document outlines a detailed, real-world process for syncing data from a third-party API into a Supabase database. It is designed to prepare the data for a variety of uses, including custom dashboards, bespoke applications, and as a knowledge base for Large Language Models (LLMs). While this case study uses Ontraport as the primary example, the principles, challenges, and strategic decisions discussed form a reusable framework applicable to other APIs.
The documentation is structured for both technical and non-technical readers. Conceptual overviews are provided for general understanding, with specific technical sections and code examples available for developers and implementers.
1. The Strategic Objective: Data Sovereignty
The primary goal of this process is to achieve data sovereignty—liberating data from a vendor’s ecosystem to gain full control and visibility. For the client in this case, syncing their Ontraport data into a self-hosted Supabase instance enabled several key outcomes:
- Reduced Vendor Lock-in: The ability to transition away from Ontraport or use it in parallel with other systems without being entirely dependent on it.
- Enhanced Data Visibility: The creation of custom Grafana dashboards to provide insights not available through the native platform.
- Custom Application Development: The power to build utility apps and specialised tools on top of their own data.
- AI Empowerment: The ability to connect LLMs to a clean, comprehensive, and accessible data source for advanced analysis and automation.
2. Phase 1: API Discovery and Exploration
Before any data can be synced, the API must be understood. This traditionally manual and time-consuming phase can be significantly accelerated with the help of an LLM.
2.1. The “Learning” Process for an LLM
An LLM doesn’t “learn” an API in a human sense. Instead, it processes vast amounts of context provided to it. The key is to supply high-quality, structured, and unstructured information about the API.
Structured Documentation (Swagger/OpenAPI)
A swagger.json (OpenAPI) file is the gold standard, providing a machine-readable blueprint of the API. An LLM can parse this to understand every endpoint, parameter, and data structure.
- Discovery: Finding this file can be a challenge. As was the case with Ontraport, it may not be publicly linked. The best methods are inspecting the browser’s network console while using the API’s documentation portal or trying common URL patterns like
api-docs/swagger.json. For Ontraport, the URL washttps://api.ontraport.com/1/api-docs/swagger.json.
Unstructured Documentation
For context and nuance not present in the Swagger file, the full API documentation should be scraped. Using a tool like Firecrawl on the Ontraport docs (https://api.ontraport.com/doc/) provided a comprehensive text file. This was then ingested via a Retrieval Augmented Generation (RAG) system into Supabase, making the entire documentation searchable by the LLM.
Direct API Interaction
Equipped with documentation and a call_API tool, an LLM can directly test endpoints. This is invaluable for confirming access, discovering available objects (e.g., Ontraport’s GET /objects/meta endpoint), and understanding the data you can actually retrieve, which may differ from the documentation.
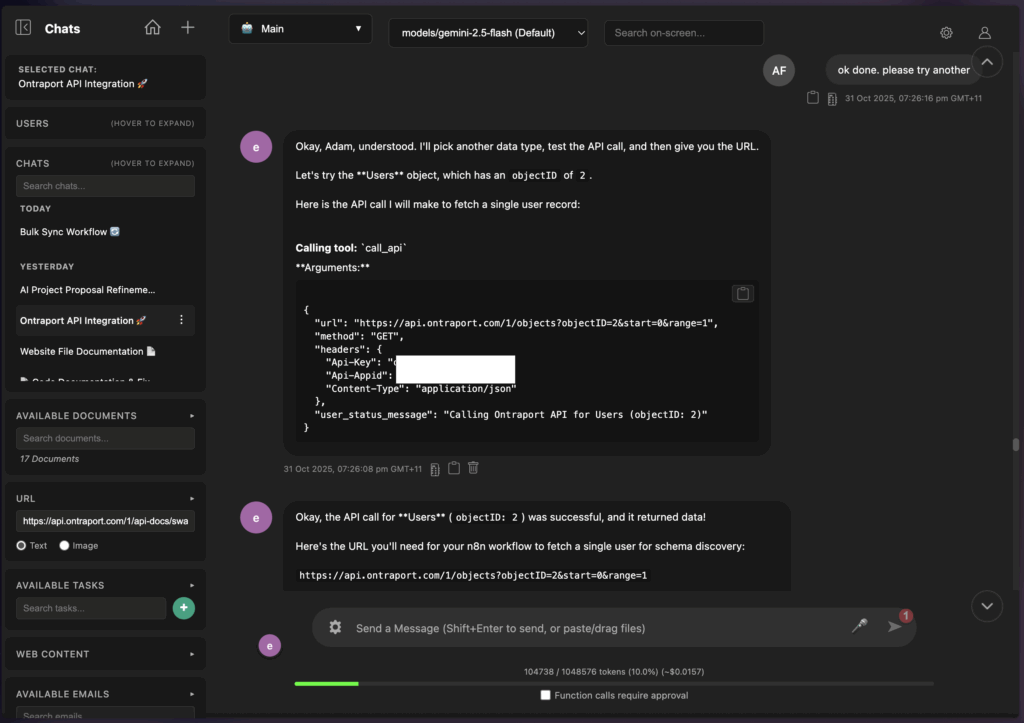
3. Phase 2: Dynamic Table Creation in Supabase
With over 100 potential data objects (endpoints) in Ontraport, creating a Supabase table for each one manually is inefficient and prone to error. The solution is to automate table creation within an n8n workflow.
3.1. The ontraport_tables Control Table
The first step is to create a central control table in Supabase. This table, ontraport_tables, lists every object to be synced, its Ontraport object_id, and the desired supabase_table_name.
While this was done manually for this project, a more efficient future approach would be to use the LLM to call the GET /objects/meta endpoint, retrieve the list of all available objects, and then generate the SQL INSERT statements to populate this control table automatically.
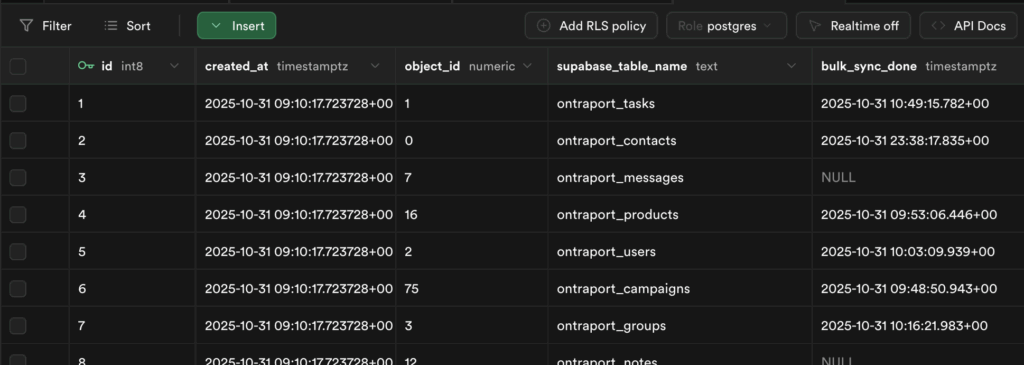
3.2. Programmatic Table Creation: A Deterministic Approach
This is a critical point: while an LLM is excellent for exploration, creating database schemas is a precise, deterministic task best handled by code, not a probabilistic model. Using an LLM to generate CREATE TABLE statements risks hallucinations, syntax errors, and inconsistencies. A programmatic approach guarantees accuracy and provides traceable error logs.
The n8n workflow performs these steps:
- Check if Table Exists: It first queries
information_schema.tablesto see if the table for the selected object already exists.SELECT EXISTS ( SELECT 1 FROM information_schema.tables WHERE table_schema = 'public' AND table_name = '{{ $json.table }}' ); - Fetch a Sample Record: If the table doesn’t exist, it calls the API to get a single record (
range=1) to use as a template. - Generate
CREATE TABLESQL: A Code node then inspects this sample record and dynamically builds theCREATE TABLEstatement. This code handles several important “gotchas”:- It sets the
idfrom the API as abigint PRIMARY KEY. The default auto-incrementing Supabaseidis not used to maintain a direct link to the source data. - It adds a
created_attimestamp for internal Supabase tracking. - It sanitises column names: converting to
snake_case, handling keys that start with numbers, and removing illegal characters. - It performs basic data type detection (e.g.,
boolean,jsonb), but defaults totextfor safety.
- It sets the
Here is the core logic from the n8n Code node that generates the query to create the tables:
const columns = [];
// Add 'id' column as BIGINT PRIMARY KEY (from API)
columns.push(`"id" bigint PRIMARY KEY`);
// Add 'created_at' column as TIMESTAMP WITH TIME ZONE (Supabase internal)
columns.push(`"created_at" timestamp with time zone not null default now()`);
for (let key in the_item) {
if (key === 'id') continue;
let cleanedKey = key;
// ... (sanitisation logic as provided in your notes) ...
cleanedKey = cleanedKey.replace(/[^a-z0-9_]/g, '_');
// Determine data type (default: text)
let dataType = 'text';
const value = the_item[key];
if (value !== null && value !== undefined) {
if (typeof value === 'boolean') {
dataType = 'boolean';
} else if (typeof value === 'object' && !Array.isArray(value)) {
dataType = 'jsonb';
}
}
// Wrap column name in quotes to avoid reserved word conflicts
columns.push(`"${cleanedKey}" ${dataType}`);
}
const createTableQuery = `
CREATE TABLE IF NOT EXISTS public."${table}" (
${columns.join(',n ')}
) TABLESPACE pg_default;
`;3.3. Data Type Strategy: Default to Text
A core principle of this initial bulk sync is to **bring everything in as text**. Attempting to infer data types like integer or date from a small sample is risky; a column that appears numeric for 10 rows might contain text in the 11th. Importing as text is the safest option to prevent data loss, truncation, or formatting issues (e.g., timezone conversions, float rounding). Data type conversion and cleaning is a distinct, post-sync analysis step.
4. Phase 3: The Bulk Data Syncing Strategy
Long-running, monolithic n8n workflows that loop for hours are brittle. They consume vast amounts of memory, make debugging difficult, and a single error can halt the entire process. A more robust strategy is to use frequent, short-lived executions.
4.1. The “Random Table” Approach
The n8n workflow is triggered every minute. Instead of syncing tables sequentially, it picks a random table that hasn’t been completed yet.
SELECT * FROM ontraport_tables WHERE bulk_sync_done IS NULL AND disable_reason IS NULL
ORDER BY RANDOM() LIMIT 1;This method offers a significant advantage: it quickly reveals if the sync logic works across all the different data types. Any API quirks or inconsistencies specific to certain objects are discovered within the first couple of hours, rather than days into a sequential sync. Once the logic is proven robust for all object types, the workflow can be left to run, gradually completing the entire dataset.
4.2. Pagination and Incremental Syncing
Every API handles pagination differently. Ontraport uses offset-based pagination with start and range parameters. The workflow handles this by looping and incrementing the start offset by 50 on each iteration until no more records are returned.
A more critical aspect is how to handle incremental syncing—fetching only new or updated records after the initial bulk sync. The ideal strategy depends entirely on the capabilities of the source API:
- By ID (Ideal): Some APIs, like Ontraport, allow you to request records with an ID greater than the last one you synced. Before fetching new records, the workflow gets the
max(id)from the Supabase table and requests only records whereid > max(id). This is highly efficient for capturing new records but will miss any modifications to older records. - By Modification Date (Best for Ongoing Sync): A more robust method is to filter by a modification timestamp. The workflow would get the
max(modification_date)from Supabase and request all records modified after that date. This captures both new and updated records. - No ID or Date Filter (The “Coda” Problem): Some APIs, like Coda’s, frustratingly offer no way to filter by ID or modification date. This forces less efficient workarounds. One strategy is to request all records from a recent but arbitrary time window (e.g., the last six months), hoping to catch all modifications, and then rely heavily on an
INSERT ... ON CONFLICT DO UPDATEstatement in Supabase to handle the duplicates. Another approach is to find other filterable parameters in the API (e.g., search for contacts by the letter ‘a’, then ‘b’, etc.) to break the sync into manageable chunks. These methods are complex and less reliable.
For the initial bulk sync with Ontraport, the max(id) approach was used for its simplicity. Once records are fetched, a Code node generates an INSERT ... ON CONFLICT DO UPDATE statement for each one. This “upsert” logic is crucial, ensuring that new records are added and existing records are updated if they happen to be fetched again.
const results = [];
for (const item of items) {
const the_item = item.json; // Each item.json is a single contact object
const columns = [];
const values = [];
const updateSet = [];
const table = $('Set variables1').first().json.table
// Add 'id' column. Ontraport ID is text.
columns.push('"id"');
values.push(`'${the_item.id}'`);
// Iterate over other contact properties from the API response
for (let key in the_item) {
// Skip 'id' as it's already handled
if (key === 'id') continue;
let cleanedKey = key;
// Handle keys starting with numbers by prepending 'f'
if (!isNaN(parseInt(cleanedKey.charAt(0)))) {
cleanedKey = 'f' + cleanedKey;
}
// Convert to snake_case and remove potential double underscores
cleanedKey = cleanedKey.replace(/([A-Z])/g, '_$1').toLowerCase();
cleanedKey = cleanedKey.replace(/__/g, '_');
// Replace any special characters (including forward slashes) with underscores
cleanedKey = cleanedKey.replace(/[^a-z0-9_]/g, '_');
columns.push(`"${cleanedKey}"`);
let value = the_item[key];
if (value === null || value === undefined) {
values.push('NULL');
} else if (typeof value === 'string') {
values.push(`'${value.replace(/'/g, "''")}'`);
} else {
values.push(`'${String(value).replace(/'/g, "''")}'`);
}
// Add to updateSet, excluding 'created_at'
if (cleanedKey !== 'created_at') {
updateSet.push(`"${cleanedKey}" = EXCLUDED."${cleanedKey}"`);
}
}
const insertQuery = `
INSERT INTO public.${table} (${columns.join(', ')})
VALUES (${values.join(', ')})
ON CONFLICT (id) DO UPDATE SET
${updateSet.join(', ')};
`;
results.push({ json: { query: insertQuery } });
}
return results;4.3. Rate Limiting
Ontraport imposes a limit of 180 requests per minute. Whilst this is ample for this example, the idea of using a short-lived scheduled executions rather than one monolithic attempt to update everything means rate limits are avoided.
{{
// Code to determine wait time between requests to avoid rate limiting by the API
// If remaining requests are low (e.g., less than 5), wait for the reset period
$('Get Ontraport items').item.json.headers['x-rate-limit-remaining'] < 5 ?
// Add 1 second buffer
waitTime = parseInt($('Get Ontraport items').item.json.headers['x-rate-limit-reset']) + 1 :
// Otherwise, wait a small amount to distribute requests
// Wait 500 milliseconds between requests
waitTime = 0.5
}}4.4. Observability and Error Logging
To maintain visibility into the sync process, the ontraport_tables table is used for logging. After each run, the workflow updates the row_count for the synced table. If an error occurs, the error message is written to the disable_reason column, which automatically excludes that table from future sync runs until the issue is manually reviewed.
4.5. The Final n8n Workflow
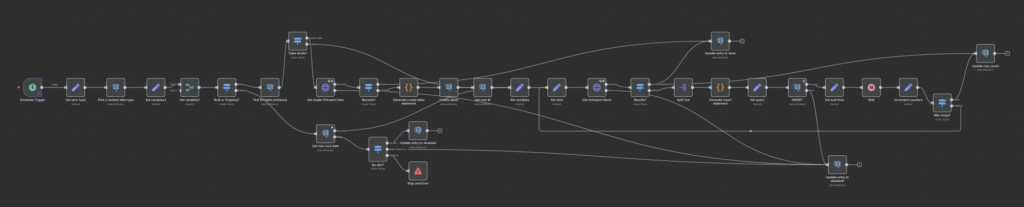
5. Handling API Quirks: The Custom Field Problem
This process revealed a major quirk in the Ontraport API: custom fields in API responses are named with cryptic IDs (e.g., f1430, f1639), not their human-readable names.
5.1. Mapping Custom Fields
The actual names (“aliases”) for these fields are available from a separate /meta endpoint, which, inconsistently, requires the object’s name (e.g., “Contacts”) rather than its objectID.
An n8n workflow was created to iterate through each table, call its corresponding /meta endpoint, parse the response, and store the mapping between the field ID (f1234) and its alias (Investment Property Address) in a new table: ontraport_custom_fields.
Again, this was done by dynamically creating the Postgres INSERT statements as required:
// Get the fields object from the incoming data
const data = $input.all()[0].json.body.data;
// Get the first (and only) key dynamically
const dataKey = Object.keys(data)[0];
const fields = data[dataKey].fields;
// Transform into array of objects, one per field
const rows = Object.entries(fields).map(([fieldId, fieldData]) => {
let cleanedKey = fieldId;
// Handle keys starting with numbers by prepending 'f'
if (!isNaN(parseInt(cleanedKey.charAt(0)))) {
cleanedKey = 'f' + cleanedKey;
}
// Convert to snake_case and remove potential double underscores
cleanedKey = cleanedKey.replace(/([A-Z])/g, '_$1').toLowerCase();
cleanedKey = cleanedKey.replace(/__/g, '_');
// Replace any special characters with underscores
cleanedKey = cleanedKey.replace(/[^a-z0-9_]/g, '_');
return {
custom_field_id: cleanedKey, // Now matches the actual column name
alias: fieldData.alias,
type: fieldData.type,
required: fieldData.required,
unique: fieldData.unique,
editable: fieldData.editable,
deletable: fieldData.deletable
};
});
return rows;5.2. The Solution: Dynamic PostgreSQL Views
With hundreds of custom fields, querying the raw tables is impractical for humans and LLMs. The solution was to create a PostgreSQL VIEW for each table that has custom fields. This view presents the data with human-readable column names.
However, creating these views manually is not scalable. A PostgreSQL function, refresh_ontraport_view(table_name_param text), was developed to automate this. It dynamically constructs a CREATE OR REPLACE VIEW statement by joining the base table with the ontraport_custom_fields table to alias the columns.
DECLARE
view_sql text;
custom_fields_sql text;
view_name text;
error_detail text;
BEGIN
-- Construct the view name
view_name := table_name_param || '_view';
-- Build the custom fields part of the SELECT (only where exists = true)
SELECT string_agg(
'"' || custom_field_id || '" AS "' || alias || '"',
', '
ORDER BY custom_field_id
)
INTO custom_fields_sql
FROM ontraport_custom_fields
WHERE table_name = table_name_param
AND (exists IS NULL OR exists = true); -- Include NULL for backwards compatibility
-- Build the complete view SQL
view_sql := 'CREATE OR REPLACE VIEW ' || view_name || ' AS SELECT ' ||
'id, created_at, owner, firstname, lastname';
-- Add custom fields if any exist
IF custom_fields_sql IS NOT NULL THEN
view_sql := view_sql || ', ' || custom_fields_sql;
END IF;
view_sql := view_sql || ' FROM ' || table_name_param;
-- Try to execute the dynamic SQL
BEGIN
EXECUTE view_sql;
EXCEPTION
WHEN undefined_column THEN
-- Extract the column name from the error message
GET STACKED DIAGNOSTICS error_detail = MESSAGE_TEXT;
-- Mark any fields that don't exist as exists = false
UPDATE ontraport_custom_fields
SET exists = false
WHERE table_name = table_name_param
AND custom_field_id = substring(error_detail from 'column "([^"]+)" does not exist');
-- Retry the view creation without the missing column
PERFORM refresh_ontraport_view(table_name_param);
END;
END;Crucially, the function includes error handling. If view creation fails because a custom field in the mapping doesn’t actually exist in the base table (an undefined_column error), it catches the exception, marks that field as exists = false in the ontraport_custom_fields table, and then recursively calls itself to try creating the view again.
6. The Problem with Templates: Why This is a Framework
It is tempting to view this documented n8n workflow as a copy-paste template for any API sync. **This is not the case.** The workflow is heavily customised to Ontraport’s specific behaviours. Attempting to apply it directly to another API like Salesforce would fail.
The value of this documentation lies in providing a **framework and a methodology**. It gives you a process to follow and a checklist of critical questions to answer for any new API:
- Endpoint Discovery: How do I find all available data objects? Is there a meta endpoint?
- Authentication: What is the authentication method?
- Pagination: How does the API handle pagination? (Offset, cursor, page-based?)
- Rate Limiting: What are the rate limits, and how are they communicated in the API response?
- Custom Fields & Quirks: Are there non-standard behaviours, like Ontraport’s custom field mapping?
Starting from this framework will be faster than starting from a blank slate, but it does not eliminate the need for a dedicated discovery and development process for each new API.
7. Phase 4: Transitioning to an Ongoing Sync
Once the initial bulk sync is complete for all tables, the strategy must shift from a one-time data dump to an ongoing, incremental process that captures both new and, crucially, **modified** records.
The most effective way to achieve this is by switching the filtering logic from max(id) to max(modification_date). The workflow for each table would then be:
- Query the Supabase table for the most recent modification timestamp.
- Call the API to request all records that have been modified since that timestamp.
- Use the same
INSERT ... ON CONFLICT DO UPDATElogic to add or update the records in Supabase.
It’s entirely possible to start with this “ongoing sync” logic from the very beginning. For an empty table, the max(modification_date) query will return NULL. The workflow can handle this by using a very old default date (e.g., ‘1901-01-01’) as the filter for the first API call, effectively fetching all records.
Note on Deletions: This strategy does not account for records that are deleted in the source system. Handling deletions is a significantly more complex problem, often requiring a full comparison of all IDs between the source and destination, and is considered a separate, advanced topic.
8. The Next Challenge: Bridging Views and Schema Modification
The sync process is complete, but it creates a new, complex challenge for the next phase: AI-driven data analysis and modification.
The architecture is now:
- On the Client’s Server: The raw
ontraport_contactstable (withf1234columns) and theontraport_contacts_view(with human-readable names). - On My Server: The
ontraport_contacts_viewis accessed as a Foreign Table, allowing the LLM to interact with it.
The Conundrum: The LLM sees and queries the clean, human-readable column names from the foreign table. However, it cannot perform modifications like changing a column’s data type or adding comments, as these operations are not permitted on views or foreign tables. Those changes must be applied to the original base table on the client’s server, which has the cryptic f1234 names.
This creates a fundamental disconnect. How can an LLM, working with the alias Investment Property Address, know that to add a comment, it must target the column f1430 on a different table on a remote server? Solving this is a significant challenge and represents the next chapter in this integration journey.
Regardless of the above difficulty, once the data is synced / imported, it immediately appears in the “CRM” environment I’ve set up which allows visibility and data interaction with any Supabase table:
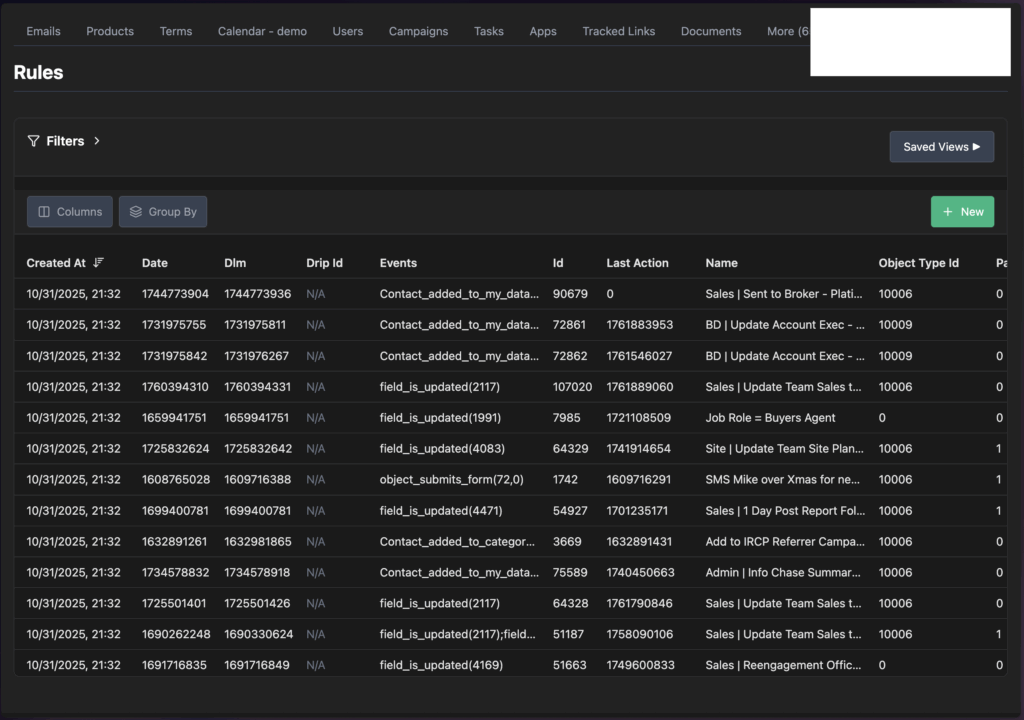
And the AI Chat app also has immediate access to all that data as it has full access to Supabase.
8 Comments