A client wanted a “chatbot” to interface with all of the providers (Google, OpenAI, Perplexity, Anthropic, and image generation models) so they could easily compare and test and use the best model for a specific purpose. My solutions connects to all providers (via their API) and allows the user to switch between providers depending on the immediate need or changes to their features.
I designed a system that works within and around the features and constraints of each platform to get the features the client need at the time I need it. And, as documents are at the core of my AI needs, I hope I’ve developed a system that handles documents efficiently.
3 screenshots of the app:
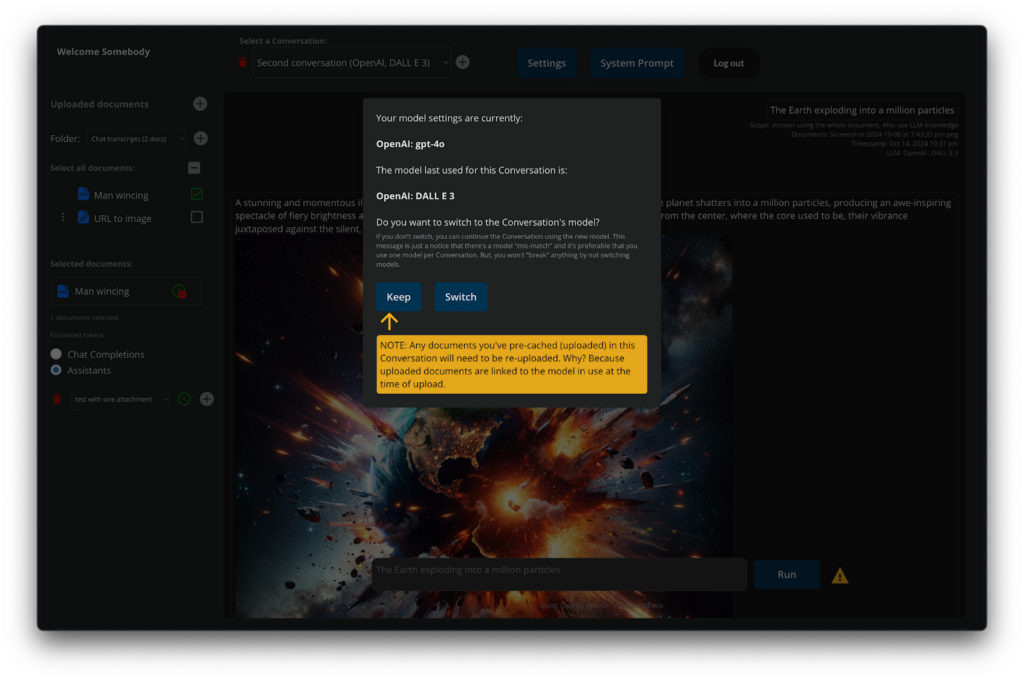
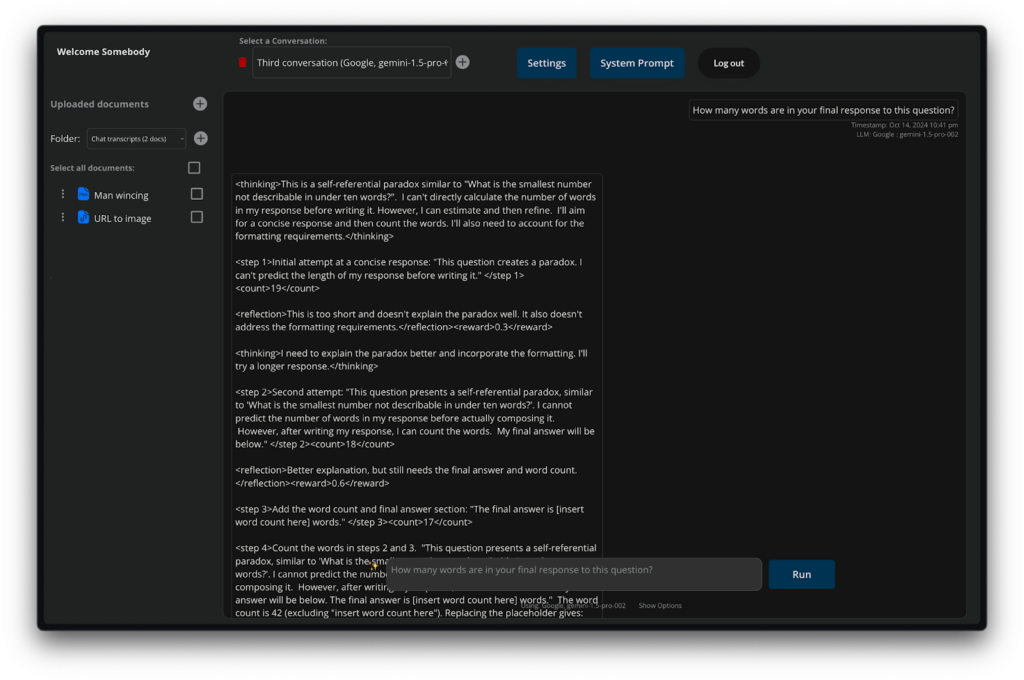
You can switch between AI providers and models quickly. If you’re not getting the desired response, just switch the model. You can even switch mid-conversation. It’ll stop or warn you if there’s any back-end issues with switching to or from a model:
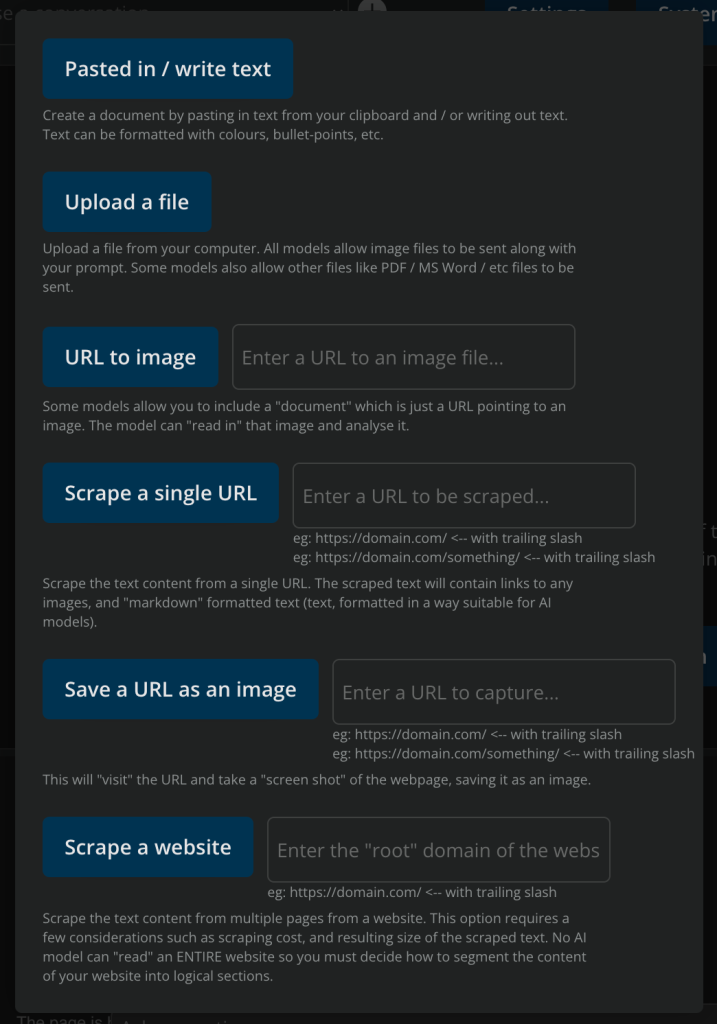
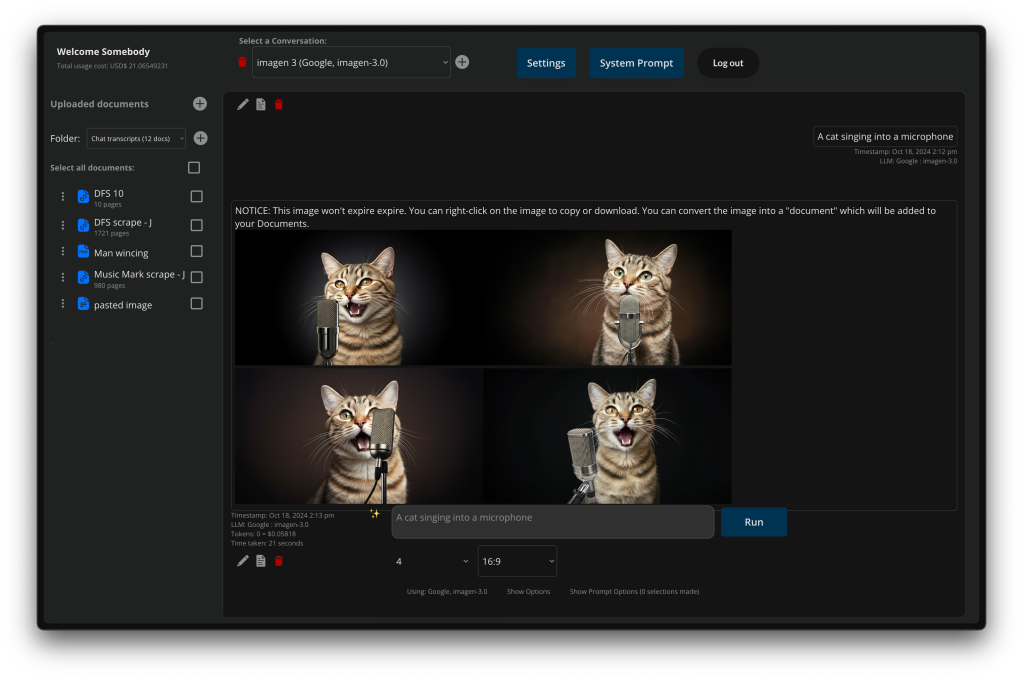
There’s a lot of options in terms of document / file management. You can add documents in a variety of ways:
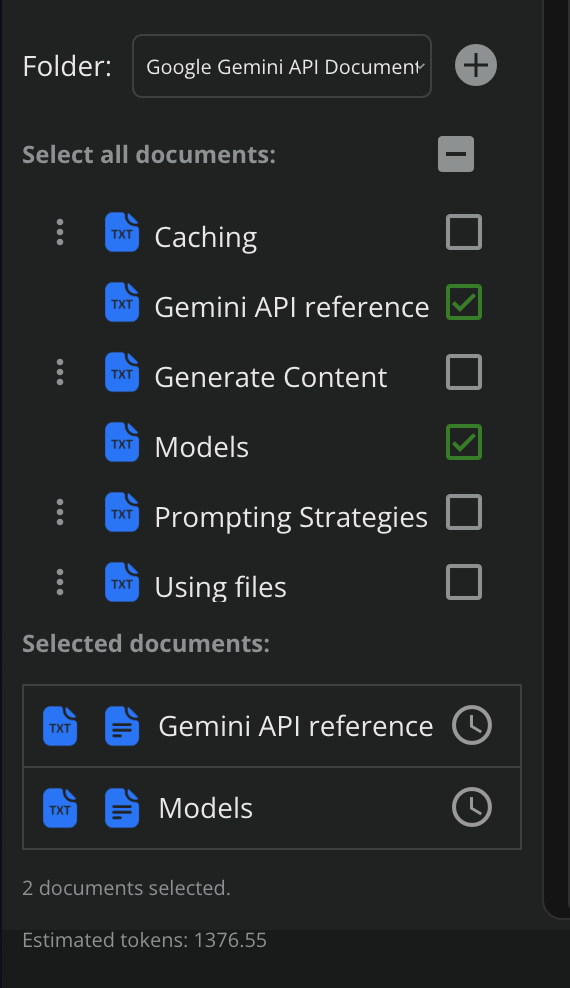
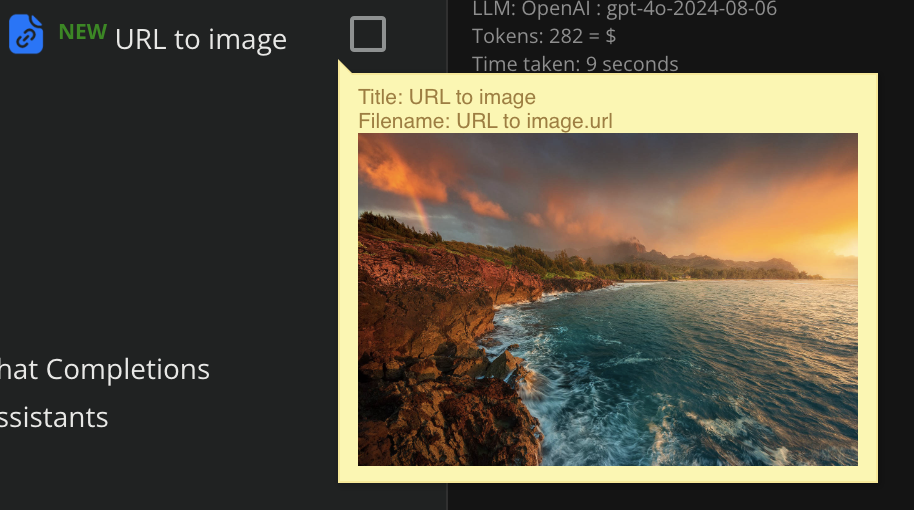
You can create unlimited folders, have unlimited uploads, it displays file-type icons & thumbnails of each document / image, and a “NEW” icon on newly added files.
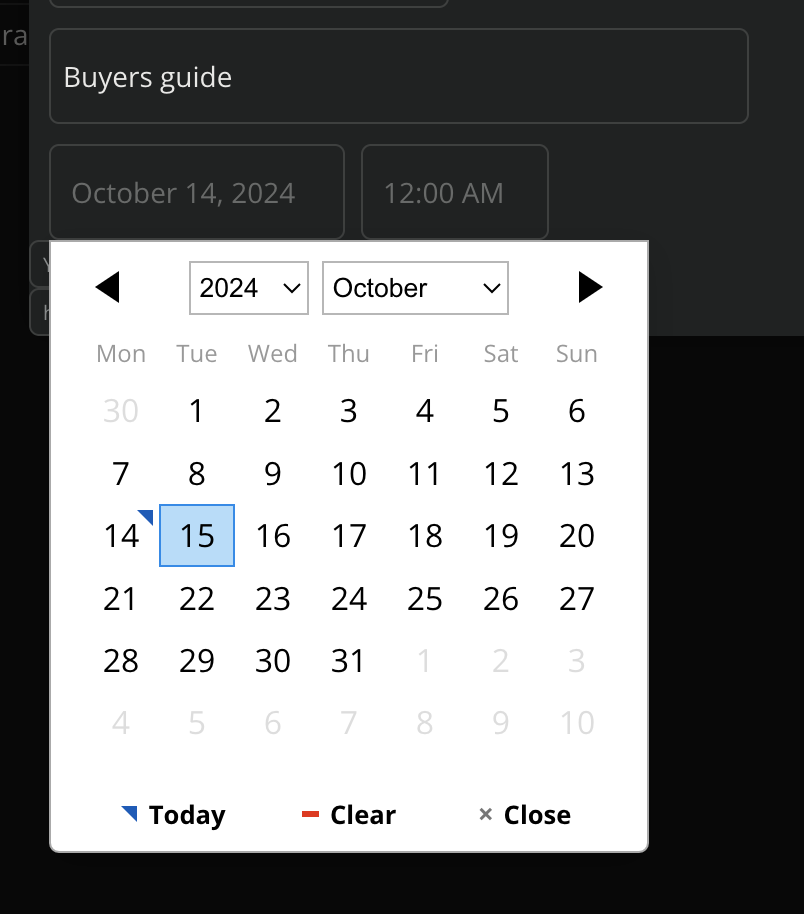
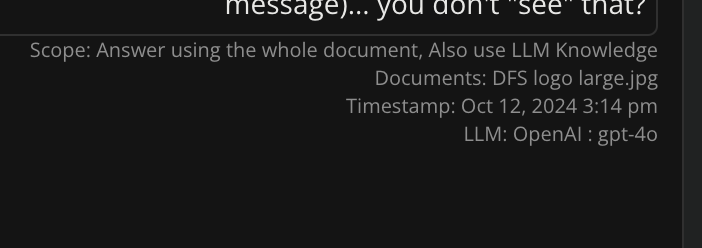
You can set the timestamps on documents. It’s sometimes useful for a model to know the order of documents (eg; meeting transcripts, emails, etc) so as to understand timelines better. Timestamps are included along with the document (when possible).
Validation to help ensure you only select the options compatible with the model, and tooltips to help you understand why.
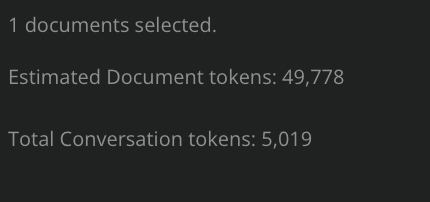
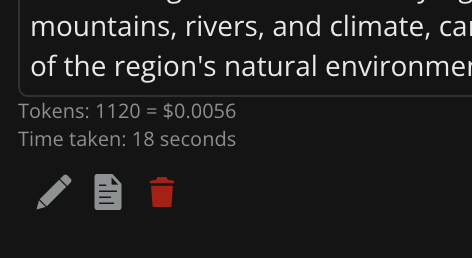
Displays estimated token size of text documents as well as the total current conversation. (1 token = 0.75 words). This allows you to know in advance how much of the “context window” your prompt + documents will consume.
The system saves the actual total token usage with each response, saves 90% accurate cost prediction for each response (including for image generation), displays the platform / model used for each response, the time taken, and which documents were included in prompts.
All conversations are stored in a database on the client’s own server. So long as the conversation history fits within the maximum “context window”, and the speed remains acceptable, you can maintain long conversations over long periods of time.
All text documents can optionally be stored in a vector database. So, if speed or cost becomes an issue you can switch from supplying full documents to the AI model to instead use semantic searching on the vector store. You can even switch mid-conversation.
I try and use full document retrieval wherever possible. I find it best to send documents along with the prompt to avoid uploaded documents being stored in a vector database by the AI server. The app allows the user to:
Attach / remove document/s on a prompt-by-prompt basis, or;
Send text documents as “inline” text with each prompt, or;
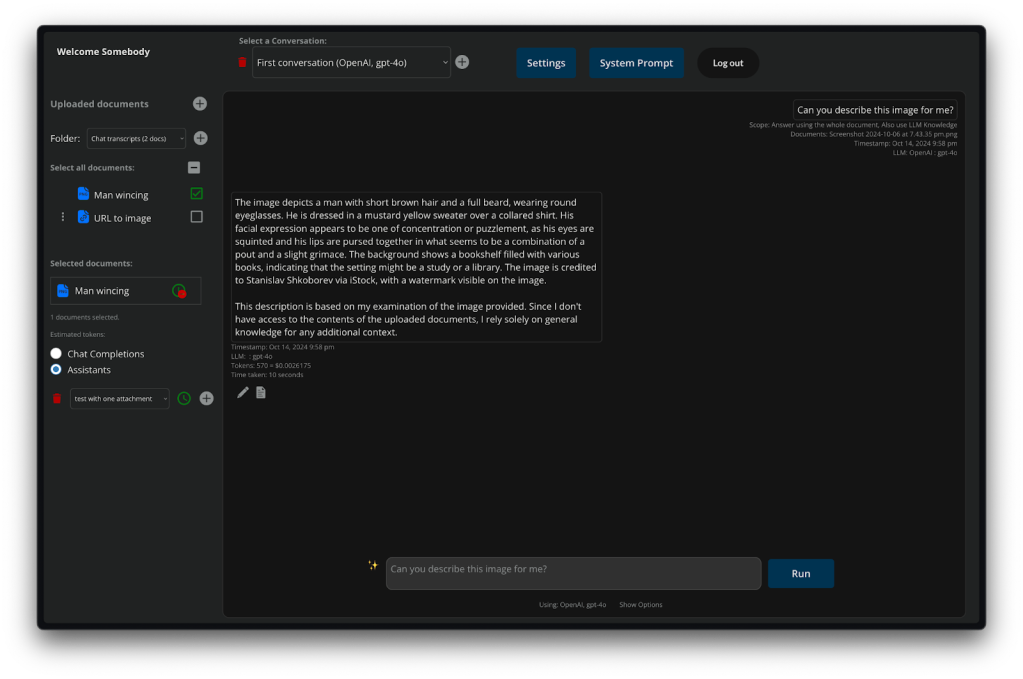
Send any document / image as Base64 encoded text, inline with each prompt, or;
For supported models, point the AI to external URLs for the information / document / imageThese 4 methods ensure you only give the AI model the documents that are relevant to the current part of the conversation, and you force the entire document to be ingested on each request. The key is that you can add in, or remove documents on each prompt to ensure the AI is only given the relevant documents at the right time in the conversation. It’s far better to say, “And looking at the document that I’m sending you now, tell me about…” rather than, “From the collective knowledge base I uploaded an hour ago, tell me about…”
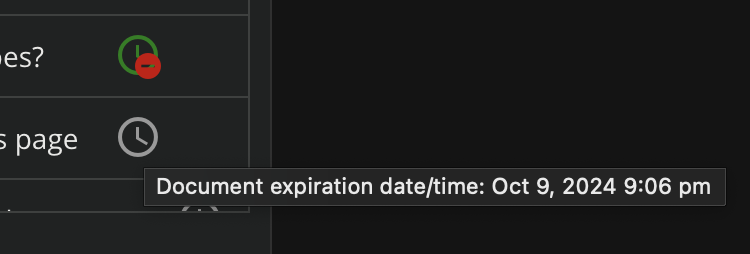
You can still upload in advance if you wish, and are notified when any pre-cached documents expire on the AI server and with one-click you can re-cache them.
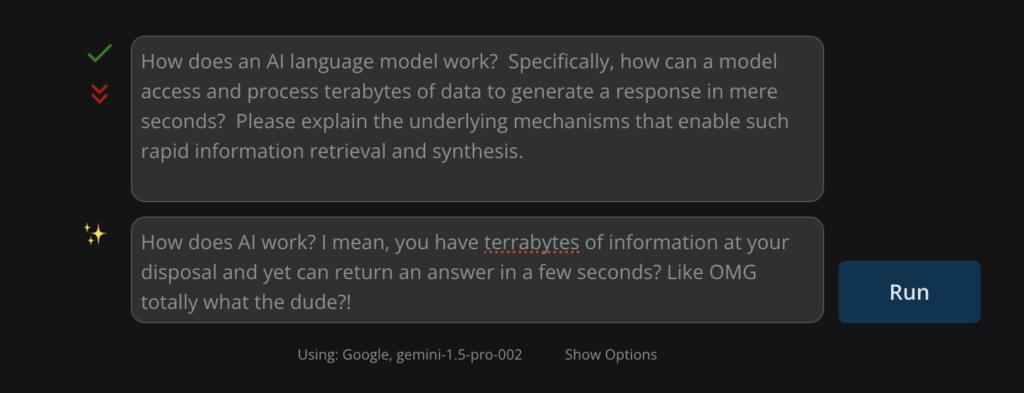
You can get the AI to improve your prompt:
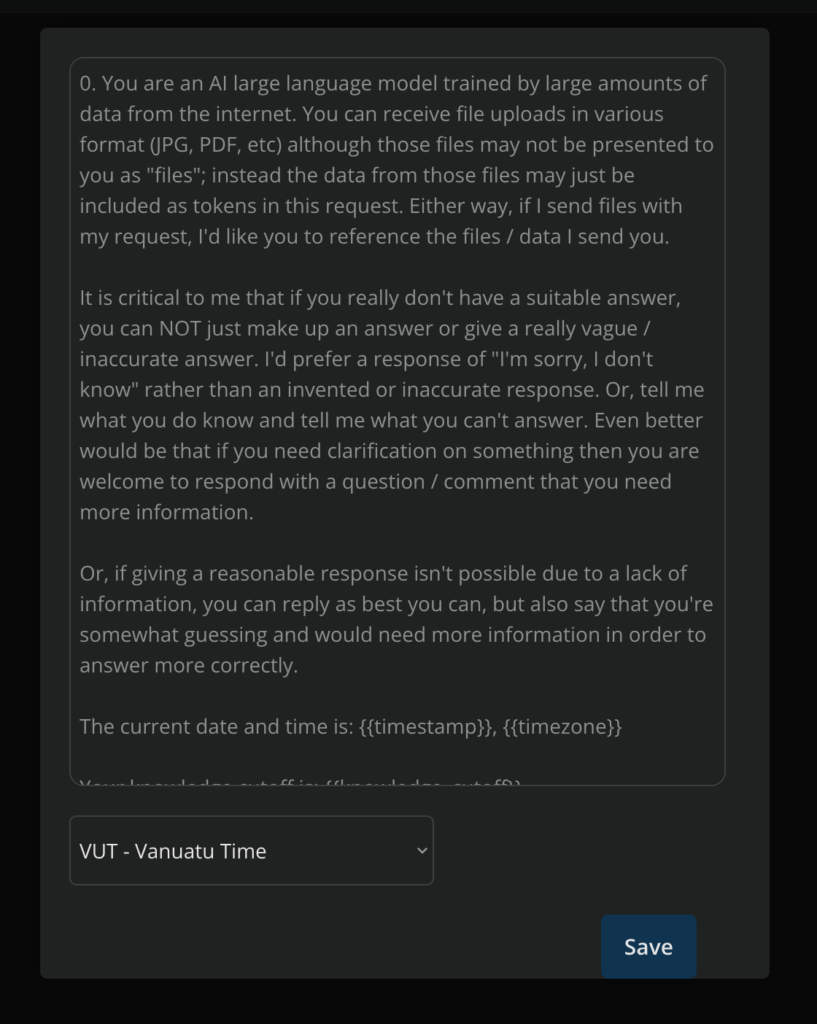
The default “system prompt” can be changed. The default prompt includes system instructions to get the best possible output. The prompt includes instructions to:
remind the model that it is in fact just a machine trained on internet content. This is important to get over the sometimes insistent refusal of the model to “see” documents, perform certain tasks, or even admit that it’s just a computer looking at tokens.
ensure responses are formatted for easier reading and easy copy-pasting into documents.
ensure the correct regional spelling / language style / word choice
not hallucinate when it doesn’t know the answer but thinks it has to tell you something, and instead encourages it to “push back” for more information. I think “prompt engineering” is a real skill.
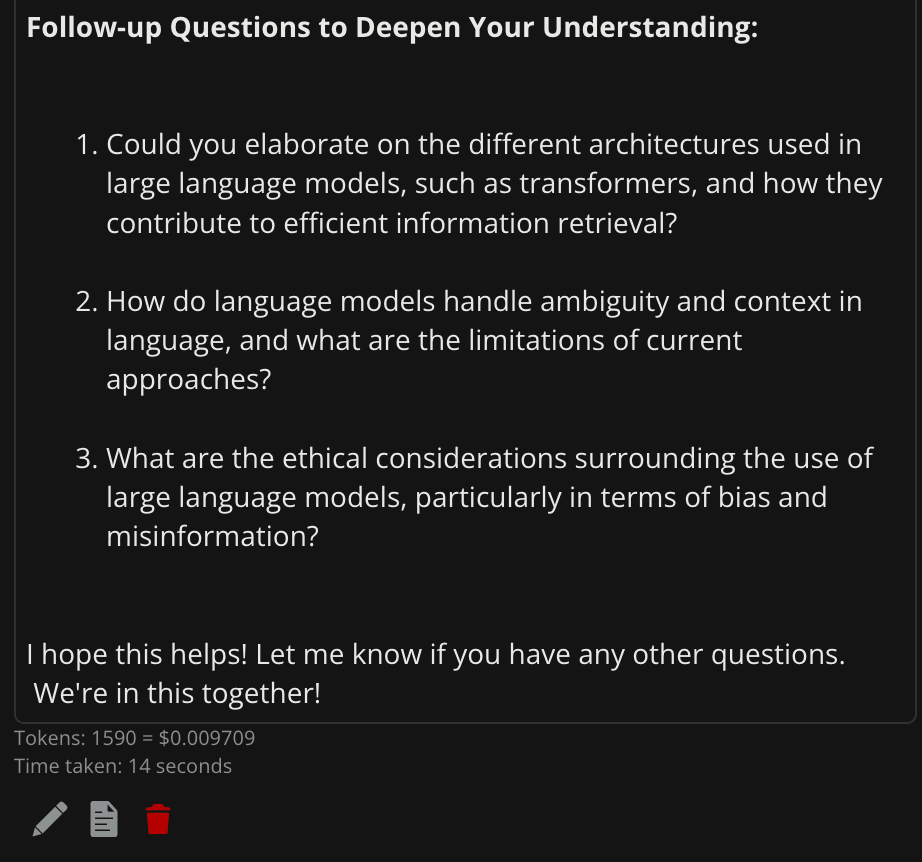
include 3 follow-up questions.
You can:
add your own “system prompt”. The default one includes merge fields to auto-insert the location, timezone, current time, and the models knowledge cut-off into the system prompt.
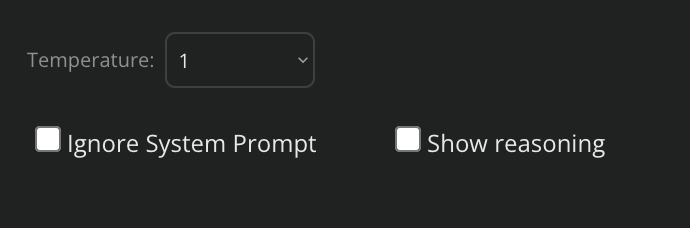
ignore the system prompt on a prompt-by-prompt basis
show reasoning with non-reasoning models:
With “show reasoning” selected, the model’s response is similar to a reasoning model’s “chain of thought” – thinking out the steps in a kind of “verbose” mode. Token usage increases, speed declines, but the quality of the answers are better and you get insight into its reasoning.
You can prompt with formatted text to give the model better understand of structure
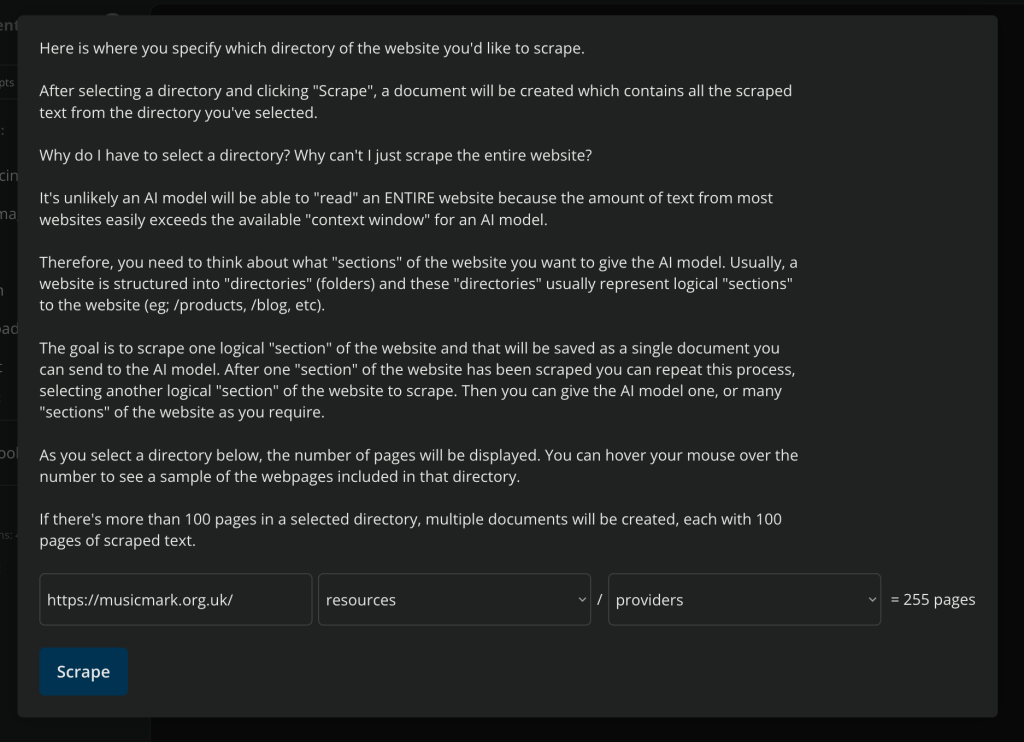
You can create a document by scraping an entire website which is then converted into a “Markdown” formatted document automatically, ready for the AI. The markdown contains links, images, text formatting, and…
Images on the webpage are automatically captioned using a vision language model and formatted as image alt tags in the output. This gives your downstream LLM just enough hints to incorporate those images into its reasoning and summarising processes. This means you can ask questions about the images, select specific ones, or even forward their URLs to a more powerful VLM for deeper analysis.
NOTE: Due to the complexities of crawling sites, I currently crawl URLs based on the site’s sitemap.
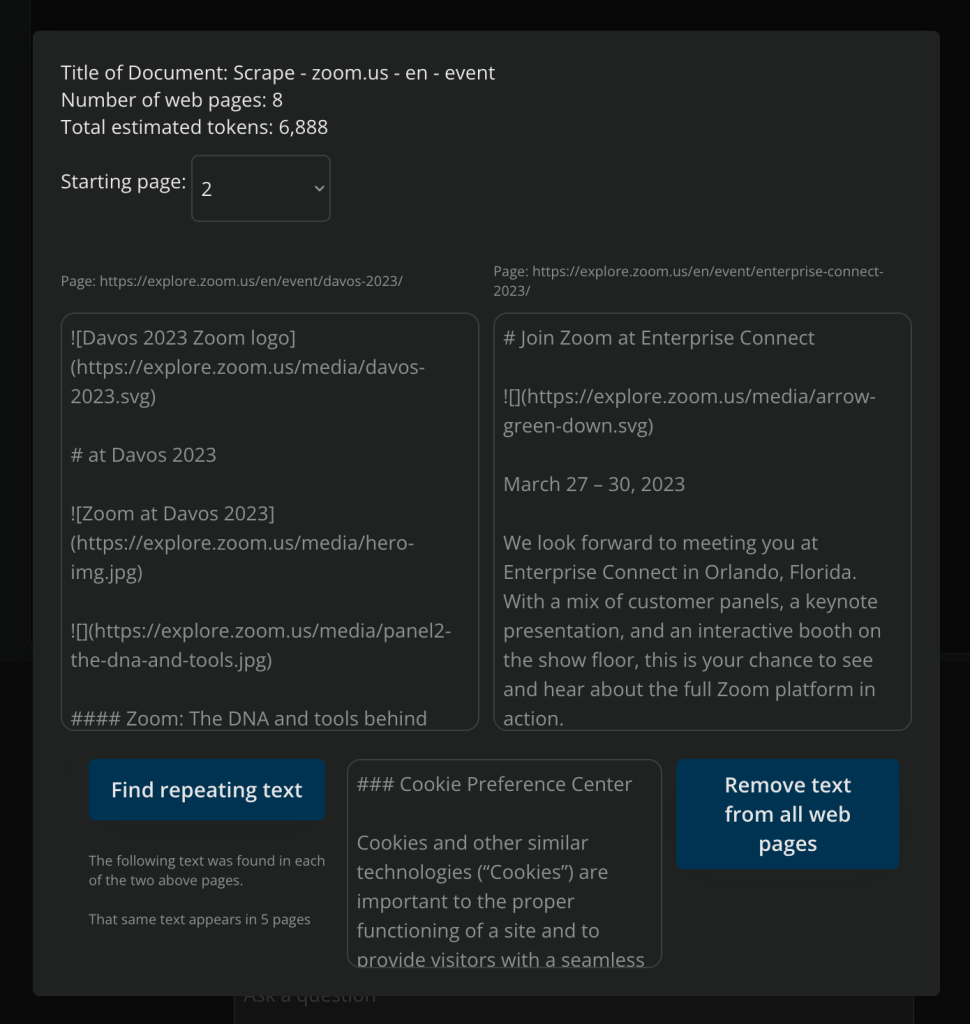
Once you’ve scraped a section of a site you can go back and compare pages, find all the pages that have the same content (such as cookie preference sections, menu bars, etc) and decide whether or not to remove those sections from all the scraped pages. The “Find repeating text” button finds the duplicate text for you. The purpose of doing is is to keep the scraped web pages as small as possible. An AI model doesn’t need to know that there’s a “cooking popup” on every page.
Once you select to remove the duplicate content, the system saves this so any future scrapes of the same domain won’t include the duplicate content you’ve previously chosen to remove.
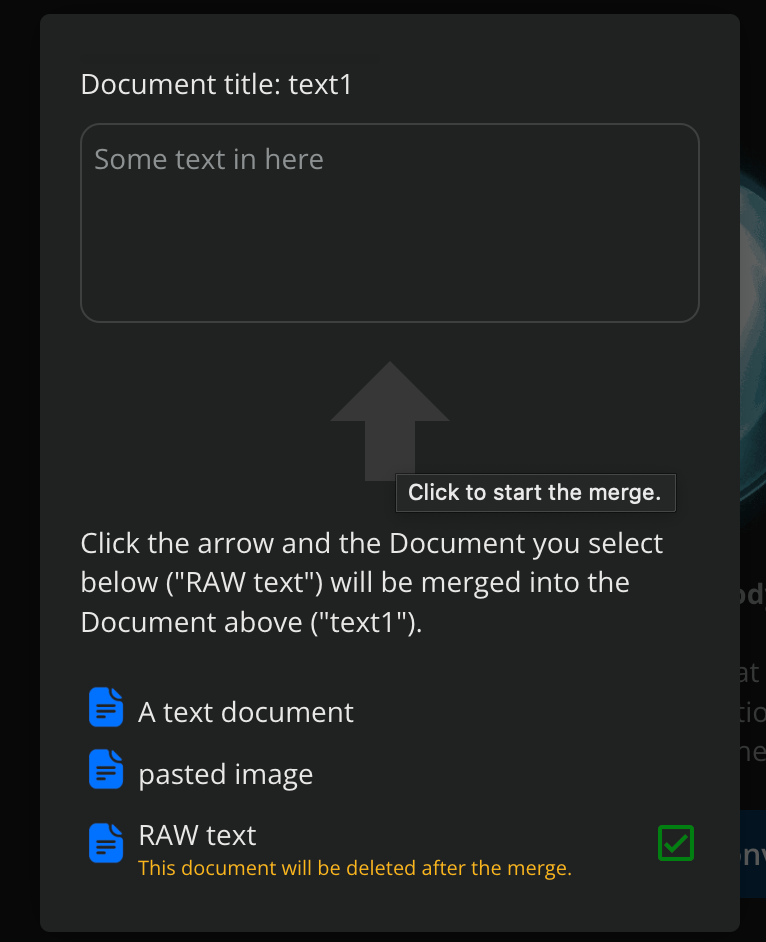
You can merge text files which is useful when a selected AI platform only allows a certain number of files.
Total costs for AI usage, scraping / crawling usage, as well as document conversion usage are totalled under the username
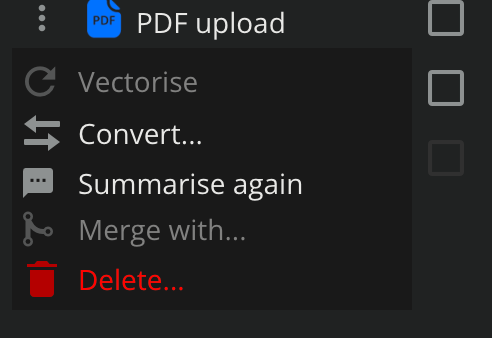
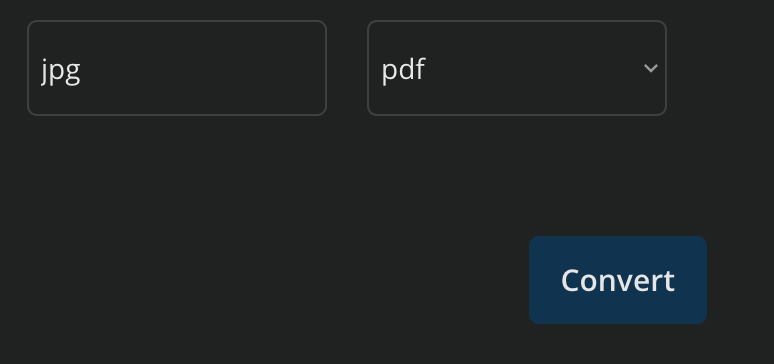
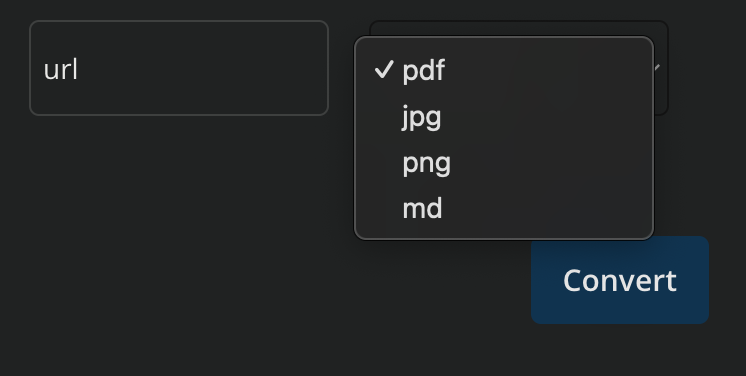
You can convert between a range of document / image formats to ensure compatibility with the model. For example, PDFs with text and images are sometime best converted to JPG and then provided to the model.
You can convert a webpage into a JPG screenshot.
You can convert a response from an AI model into a document (or an image file) with one click, and with one more click add it into the pre-cached documents to feed it back into the conversation.
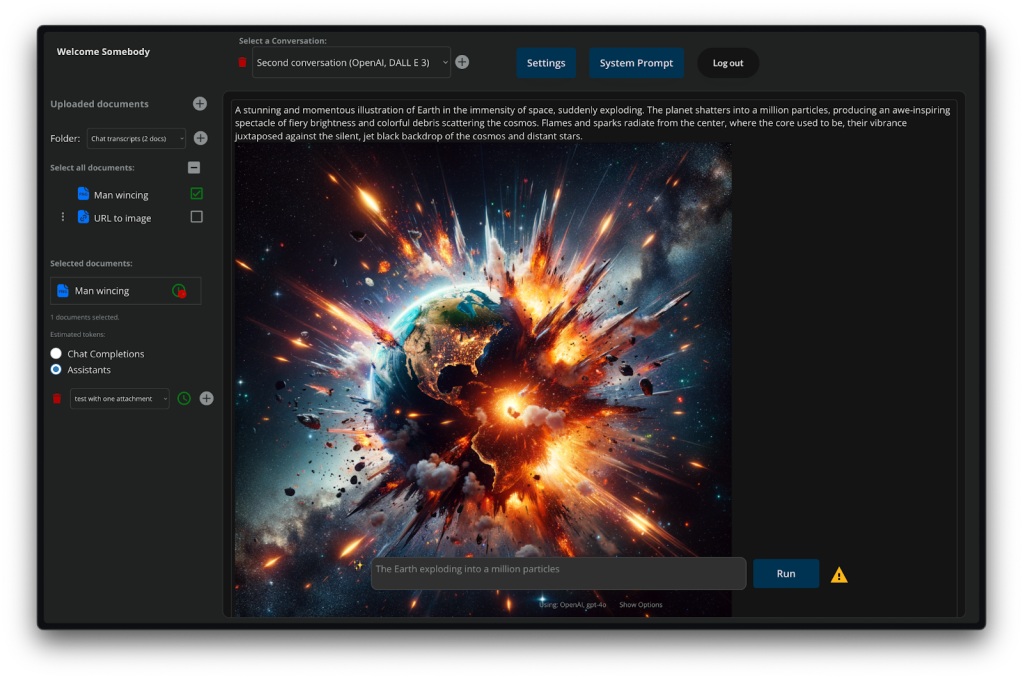
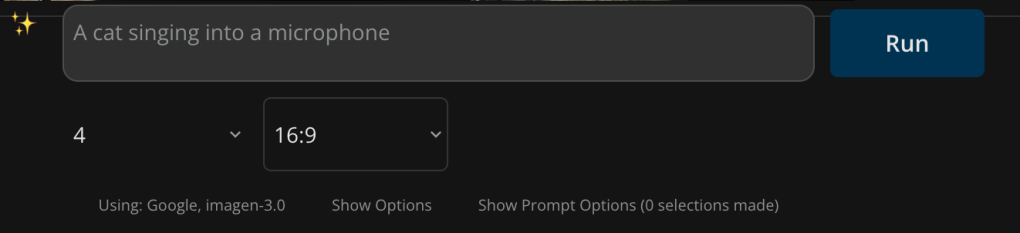
For image generation you can select the number of images and the aspect ratio:
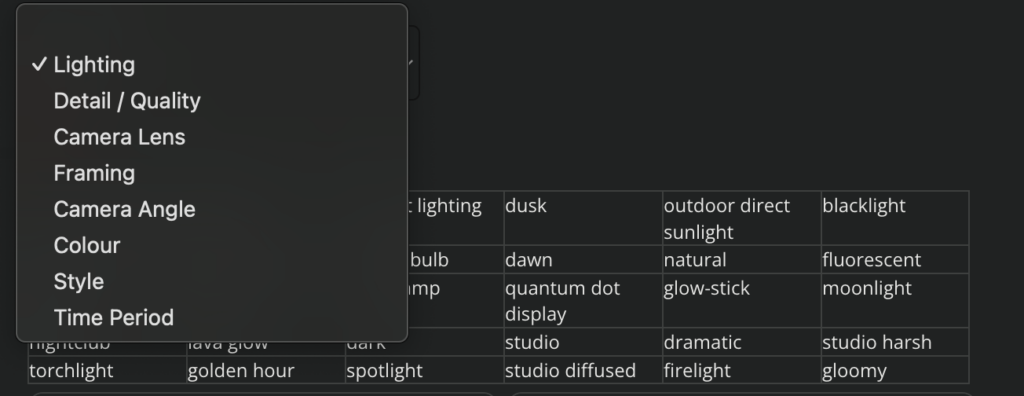
For image generation you can select from a library of terms to better describe the style, quality, and format of the output image.
You can switch between models quickly and use models where you can provide a reference image for tighter control over the result.
All these options do increase the complexity of the UI but it also allows you to test, compare, refine, and learn… and get far better results than other platforms.
One of the image API’s I’ve integrated with is Replicate. With Replicate I can easily train a model on my own images and add those new models to my app.
Limitations:
My original goal of being able to give “unlimited” documents / images to an AI so it had a huge grounding of knowledge and a long context is not (easily) possible. Even after all this development, I’m hit with limitations. OpenAI with “Assistants” is close to a solution but they only accept a maximum of 20 documents per Assistant. Currently my app can only merge text files but being able to merge PDFs and other documents would be helpful in order to overcome the file quantity restrictions. I look forward to the day when memory and speed issues don’t limit the functionality of AI. Some specific limitations are:
Doesn’t cater for streamed responses or voice input.
I haven’t implemented any “function calling” features.
I haven’t made use of OpenAI’s vector stores as my app handles that. I am using their API to get embeddings for my own vector store with Pinecone.
For now, many settings to adjust the response are not accessible by the user; I’ve hard coded them.
demodomain








17 Comments