My issue with all AI providers / models
-
demodomain
- . February 13, 2025
After paying for a subscription to each provider’s retail-facing AI, testing them, and then testing their API features, I realised they all have intricate differences which actually play out to major deal-breakers for me. I feel retail-facing AI and even AI provided by an API:
- have time limits that conversations / uploaded documents are retained. When a conversation expires, you have to start again, losing all context.
- may modify your prompts when using the retail-facing product in order to ensure the AI responds in a way that represents their brand in the way they want.
- censor the text and image outputs. This is done to protect themselves from copyright / privacy issues, and ensure no one is offended by a response.
- generally provide responses that are overly polite and considerate whereas I want responses that insist I provide better information and I want responses that challenge my own ideas.
- impose rate limits, downgrade you to a smaller model mid-conversation, and keep the better models hidden from public view.
- often can’t process files in the way advertised. PDF “reading” is often problematic.
- models are trained to “lie” in the absence of an answer. Hallucinations and misleading information is often the result. Perplexity does this a lot; Perplexity is marketed as a “research tool” and so is trained to give formal, confident answers… even when it perhaps doesn’t know the answer. I feel I get more “bullshit” from Perplexity than other models as Perplexity will never say, “I don’t know”, or “I assume…”
- lack of concrete information about the platform features. Answers in forums and even official documentation often suggest to “try x” or “try y” when things don’t appear to be working.
- restrictions are often dynamic “based on available capacity”.
- For file uploads (for RAG), there are always limits; Perplexity Spaces (50 docs), Google NotebookLM (50 docs), OpenAI Assistant (20 docs)
- store your uploaded documents in vector format (“chunking”) meaning full-document queries (like “summarise this document” or “compare document x with document y” don’t work as expected.
- Even those that don’t chunk your data (Claude Projects, possible NotebookLM)… there’s no way to get token estimates, and you can easily fill up the context window with documents leaving you with no room to actually have a conversation. And if documents take up 90% of your token limit, then after a few conversation turns you hit the limit and have to start a whole new conversation
- charge your per month (instead of a PAYG system making testing / using multiple platforms expensive). I believe this is key. I just can’t accept rate limits that vary depending on load, especially when I’m paying a fixed price each month. I need certainty that my conversation won’t be cut short. I only want to pay when the system “works”.
- don’t allow you to switch mid-conversation between using a vector search (for specific information requests), or full documents (for summarisation, brainstorming, translation, etc). This was a key issue for me.
- don’t allow you to modify the chat history (delete or modify responses, retract questions, etc) on the fly (meaning once a chat becomes “polluted” with a hallucinated answer, you have to start a conversation again).
- don’t allow you to switch between providers (obviously) mid conversation. There’s no point in using / paying for a larger / smarter model when a particular conversation you want to have only requires a smaller / cheaper model. Or, you want to generate some images from a text prompt when in the middle of a text conversation with a text model.
- don’t allow editing of uploaded documents. You have to delete the document, edit it, upload it again
- allow limited file types and no built-in features to convert into a supported format
- often my documents are more easily accessed online, or only in a certain format, or I want my “document” to be the contents of a URL. Maybe I want to just type some notes and save that as a document. I don’t want to be locked into just uploading files from my PC.
But the biggest issue for me was that these AI providers generally try to minimise storage costs, latency, and memory use by restricting the way the AI references uploaded documents, and remembers conversations. I understand why they do this, but it’s a problem for me. The AI may store uploaded documents in embeddings (vector stores) whenever it chooses in order to maintain data retrieval speed and manage storage costs. This means the AI will only access the “relevant” portions of the documents in order to address your query. You often have no control over how the data is “chunked”, or what methods and settings are used to retrieve the data. The provider may also trim messages from “long” conversations. This means the AI loses context from the oldest messages, or even sometimes the middle of conversations.
This was a key factor in deciding to code my own system. Very often, I want the AI to:
- help me brainstorm
- summarise documents
- compare documents or even sets of documents
- translate or re-structure an entire document
- clean up chat transcripts
- understand my obtuse references to something, often buried in some document somewhere
- And for data, I want to perform SUM and aggregate functions
These things can only be done if the entire document – and all documents – are available to the AI and that it’s able to retain long chat histories. For me, cost and speed are not important as I feel the costs are negligible, even for the most token-intensive tasks. I’m also happy to wait for a response if it’ll save me an hour of research.
Below is a screenshot from ChatGPT where I asked it to output all the text from the PDF. It proceeded to summarise the PDF instead:

And, in the rush to market, each provider is releasing features which quickly change, or are even revoked (for example, Google’s Imagen)… and then restored (as of writing this I just discovered Google’s Imagen is relaunched!). Costs and restrictions are changing. I don’t think it’s possible to research it all, make a decision, and for that decision not to be undermined by some new development next week.
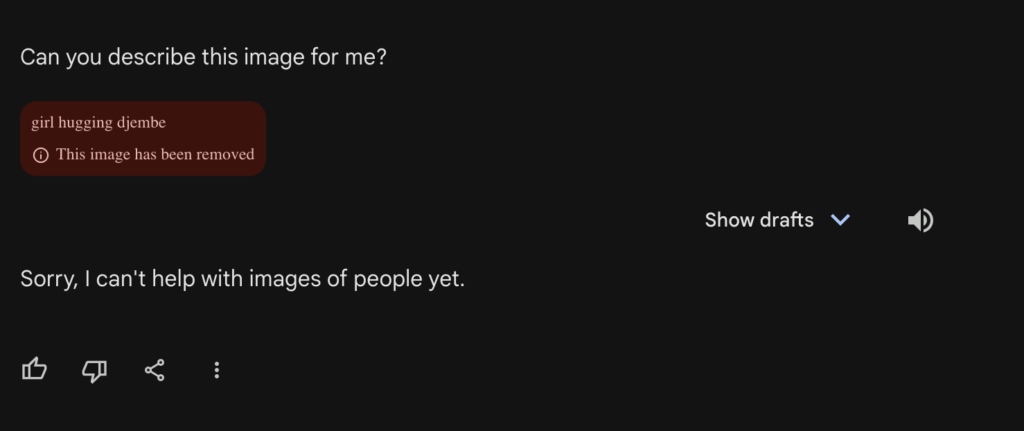
Apparently Gemini can receive images as inputs. I asked it to describe an image and it refused with this reason:
Overall, I found all services I researched to not live up to the features they advertised. What made it most frustrating is certain functions would sometimes work, sometimes not. I’ve come across many comments in forums where people are debating the capabilities of a model with each person experiencing varying levels of success.
I think it largely depends on your prompt but how many people have the time to learn about “prompt engineering”? For example, I found that I got better results if I didn’t tell the model I had uploaded a file and instead just asked a question that was related to the document. But this “trick” is not workable for me. I need to have a “frank” discussion with the AI about various documents, otherwise I’m just hoping my question triggers it to reference the correct document.
And don’t bother asking the AI directly about it’s abilities:
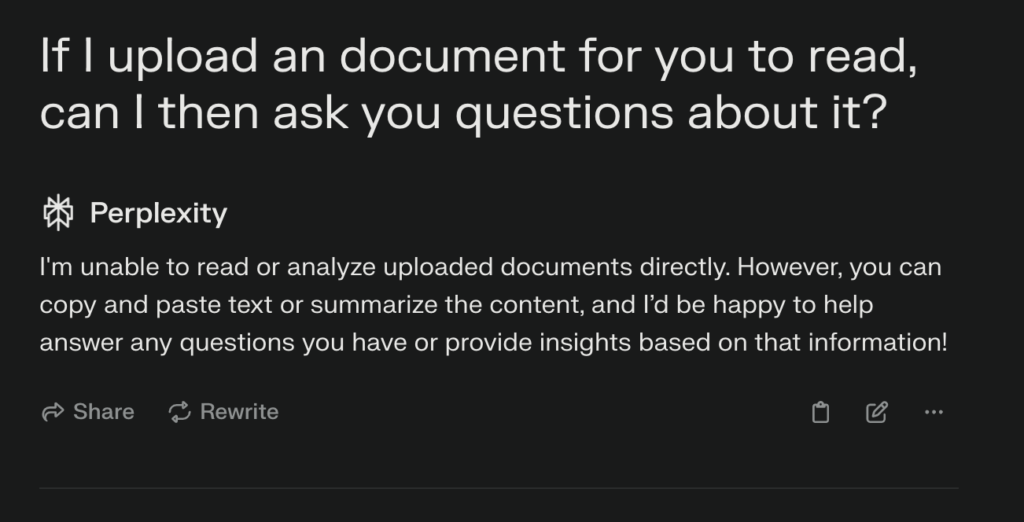
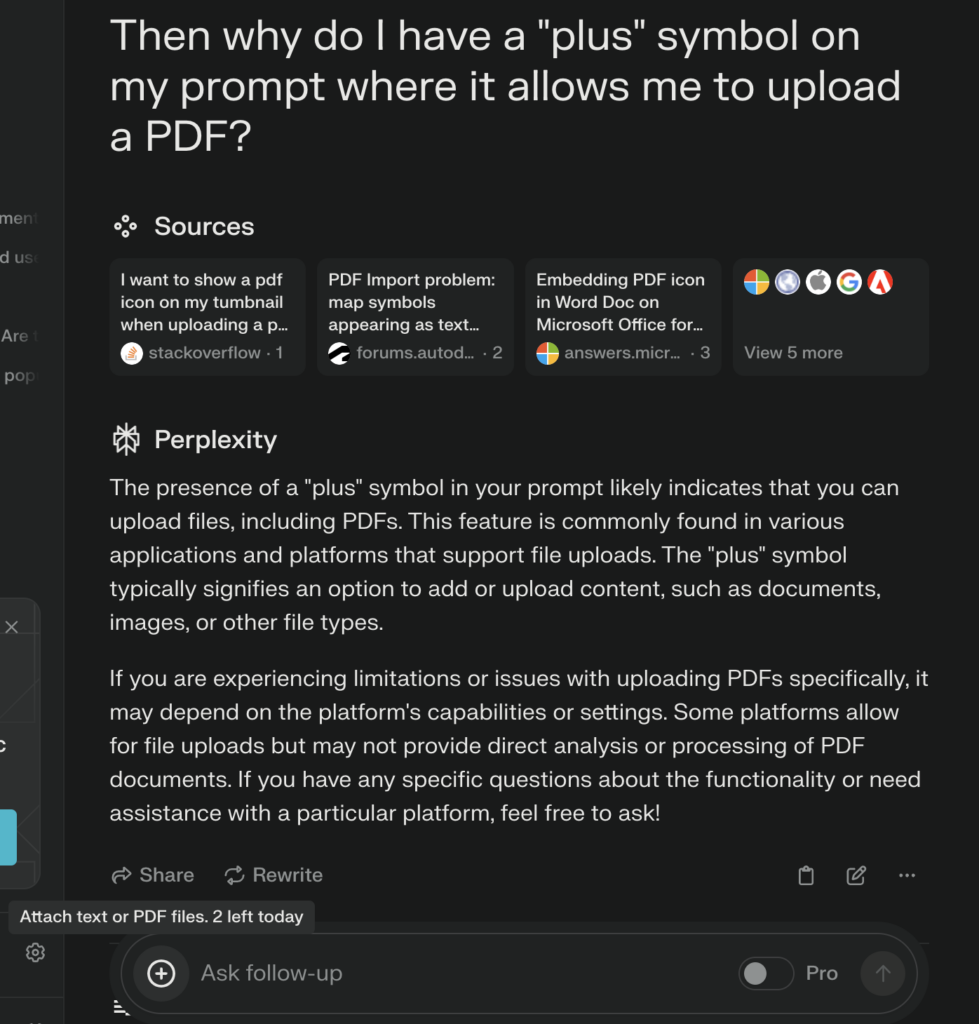
Perplexity CAN read PDF files. If I upload one, it’ll read it.